
4. Thinking Like Humans: Exploring the Potential of GPT-4 Applications
What's behind the sudden improvement in AI efficacy. Why generative text models will always have a leg up. What use cases will emerge in the second wave of GPT-4 applications.

First BERT. Then GPT-3, DALL-E, Stable Diffusion, Midjourney - all the latest in the world of AI, and all the result of an advancement in machine learning (ML) modeling called transformers. This breakthrough technique adds an attention mechanism to neural networks, a key component with next generation text and image generation with AI. In layman's terms, the attention mechanism within a machine learning model tells the rest of the neural net which part of an input it should focus on during image or text generation. For instance, given an English to French translation task with the input “My bike is shiny and red”, the attention will progress throughout the translation process, focusing on the different key parts of the English sentence as it creates the French text. Halfway through the translation, the model may have output “mon vélo est …”, and then the attention mechanism would likely tell the neural net to focus on shiny for the next output word (with some focus on the surrounding words like bike and is). While this is a contrived example, Midjourney and Stable Diffusion use an analogous attention mechanism for generating images with complex prompts, iterating through each part of the prompt and ensuring it gets included in the generated image.
When the transformer model was first published in Attention is All You Need (2017)1, it was followed shortly by the release of BERT by Google, a trained transformer text model. BERT made significant improvements over the existing state-of-the-art models, namely LSTM or GRU, for translation and other text based tasks, like summarizing and word prediction. And while any significant improvement should be celebrated, and while transformers intuitively seemed like a good technique, what came in the years following was surprising. What felt like an add-on for incremental performance appears to in fact be a major turning point in AI technology which has resulted in breakthroughs across image and text generation.
It's difficult to distribute credit precisely. While Attention is All You Need will almost certainly go down as a seminal paper, the adoption of transformer models was also accompanied by ongoing increases in compute resources and a commitment to large models from OpenAI that was previously unseen. Increased model size and training data along with the transformer model is the combined straw that broke through the camel’s most recent hump. For me, I'm inclined to believe this is an instance of power increases. Take a look at the time required to break a password of length n.
See how quickly things gain traction and escalate seemingly out of nowhere. Those powers really don’t matter, until they do. It’s quite possible that transformers + a 10x scale in model size and training data size is now driving us into the next echelon of machine learning models. Change is no longer incremental.
6 Months of Daily Work with GPT-3
As a software engineer, I’ve always been frustrated at how long it takes to go from a fully thought-out concept to a finished implementation. It simply takes too long to write down and wire up code between different components and architectures and systems, even when you have a very precise idea of what needs to be done.
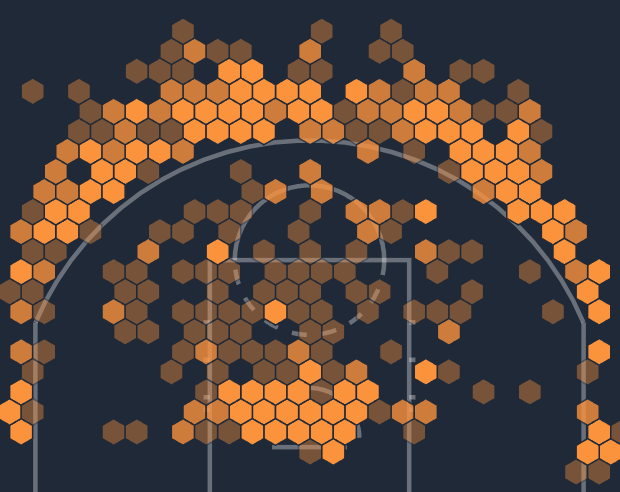
For instance, take the above shot chart which shows the most common shot locations for Steph Curry. Say I want to similarly create a defensive version of this shot chart, which shows the most common locations that Steph Curry defends shots.
(i) It takes less than 10 seconds to understand what this means conceptually.
(ii) In 10 minutes, I have a great idea of how this can be accomplished using a data set which has the location of every player at the time of each shot. In short, find the closest defender on each shot and if they are within some threshold of closeness label them as the defender for that shot. Then, similar to how we're drawing the above shot chart, bin these by defender shot location and draw the chart.
(iii) It then takes 20 - 30 hours to write the database queries and API endpoints and front end components to stitch all of this together. This is by no means rocket science, it just takes time. It's predictable, and dull, and frustrating.
The frustrating gap is this third step, going from knowing how software should be written, to actually writing it. As long as this gap exists between ideation and execution, there will be a convergence of better developer tools and no-code tools. Copilot by Github (Microsoft) is the latest in the area of developer tools. It is a code editor add-on which can predict and write code for you. And, like many new developments in AI, it is powered by a variation of Open AI's GPT-3 (Generative Pre-Trained Transformer), a massive 175 billion parameter transformer model for predicting and generating language.

Working every day with Copilot for the last 6 months, it saves me somewhere between 5 and 20 hours of writing code per month out of the roughly 120 hours of coding work I do on a monthly basis. No small matter. In particular, it is helpful in filling out repetitive tasks, working with unknown APIs, and forming basic functions that I could noodle out but it would take 5 minutes.

Copilot takes on the challenge of reducing the time-to-implementation of step (iii) above. Of course, the architectural work is still left to the programmer. The difficult conceptual and contextual work of figuring out where in the broader context code should live remains, and how it should interact with external pieces is, for now, outside of the scope of Copilot.
Prediction: The next major step for Copilot will be “prompt to pull request” capability.
I believe the next big Copilot advancement will be incorporating the broader context. Such capability would take Copilot from a next line prediction tool to a context-aware model that has some understanding of the interworking parts of a system of software. Imagine Copilot being able to take a technical spec for a feature and turn it into line-by-line code change suggestions across multiple files. The fact is, Github already already has precisely the training data it needs for this with open source pull requests. Conveniently, Github can even track feature development spanning multiple codebases thanks to their UI feature to link issues and pull requests across repos. I’d bet they didn’t plan on this use case when they added the linking feature to their UI.
For the non-developer, pull requests are a chunk of code changes to be made all related to a particular feature. I would open up a PR to create the defensive shot chart.
Emerging GPT-4 Use Cases
Copilot, which is built on top of a version of the GPT-4 model, gives one very specific application for this big recent step in AI technology. The variant is called Codex, and is specific to coding, a very particular form of language filled with technical syntax and finely articulated structure. In general, though, GPT-4 is a generative text model for human language as we speak it and write it on an everyday basis. Generative meaning that, given a prompt or pre-text, outputting the likely subsequent text.
In my opinion, the effectiveness of GPT-4 and our fascination with its results tells us just as much about ourselves as it does the models. Even before GPT-4, generative text models have always “outkicked their coverage” - seeming to be ahead of their time in comparison their other machine learning counterparts. RNNs quickly attracted the label of being "unreasonably effective".2 I think this arises from three factors.
I. First, word-by-word generative output is a whole lot closer to how we speak and write than we think at first glance. Text generation is something we do every day, but hardly think of it as such. When we speak, we very rarely know the full sentence before we speak it. We know roughly where we want to end up, but in large part speaking, and writing, is us taking a little stroll around our neurons and mental models and blurting out what feels like the right thing to say. It’s hardly a fully conscious effort; it’s based in large part on subconscious intuition. This is to say, the neural net models used to generate language word-by-word may pretty closely map to how we generate text in our own brains.
II. The second important feature of generative text models is the ubiquity of language within our lives. Language is our primary means of communicating information from one mind to another. To us, it makes for a very natural way for us to both output information, as well as receive it. Both directions key for for the success of generative text models. Compare the ease of I/O with ChatGPT compared with training a regression model for predicting house sales price by uploading a giant CSV and being sent back another giant CSV with predicted house models. The feat may be equally or more impressive, but its difficult for us to tell. With text models, we are talking with AI in our natural medium.
III. Thirdly, as a corollary to the ubiquity of language, text models like GPT-4 can approach general intelligence for the subset of all tasks which can be described strictly with text input, and solved strictly with text output. As a species that poses questions and relays ideas and communicates full mental models predominantly with text, this is a massive subset of tasks. I would further argue, that because of our natural ability to communicate with language, we as humans have organized the bulk of our knowledge based tasks to be language based. Our teachers and bosses ask us to write written reports. We read books and research papers to stay up to date in our area of expertise. If our brains were differently equipped, software developers might spend their days drawing diagrams instead of writing code, a variant of our written language. Similarly, we may describe our weekend to our friends by acting it out, heavily relying on the visual cortex for information communication. As it is, however, we seem to be most efficient and effective with language as the vehicle for communication.
Language models dating back to the first recurrent neural nets (RNNs) have been ahead of their time because the models (i) naturally mimic our own thoughts, (ii) can both receive and relay information in a form that is natural to us, and (iii) are equipped to perform a wide variety of tasks naturally as we have designed them for ourselves as humans which text as the primary vehicle for information transfer.
OpenAI, likely seeing the incredible breadth of potential applications, did something very interesting when they released their GPT-4 model for public use. Instead of building out a consumer UI for anyone to come and use the model directly, they focused on building an incredible developer API for other companies to build on. As a result in the past two years, hundreds of companies and products have been formed on the back of GPT-4. Many of these products serve a simple role as a thin wrapper around the underlying GPT-4 model, with some task relevant UI to guide the end-consumer. For instance, Lex is writer focused, Mark Copy for writing marketing material, Rytr for fiction writers. While some prompt architecture and fine tuning goes into each of these, they are all more or less applications that, given an existing sequence of words, calls on GPT-4 to predict the next 25-50 words, and produce these for the consumer.
The upside to next-sentence generative applications like these is primarily helping us to pull information from our own brains and better articulate our thoughts. I believe these first wave applications have limited upside, along with tangible downside. They are most popularly used today populating company blog posts and marketing pages.
With better prompt engineering, I think there will be a second wave of more interesting applications. We know that this massive GPT-4 model carries a ton of information, and we’re likely only scratching the surface. I think we can do a lot better than fill in the blank for marketing copy.
In my opinion, the discovery of this second wave of applications has already been kickstarted with ChatGPT, an interactive variant of GPT-4 released directly from OpenAI in November 2022. Within a month of its release, ChatGPT quickly turned into a $100,000/day experiment3. The interactive nature of ChatGPT, as well as its approachability with the general public is the perfect storm needed for prompt discovery - a crowdsourced effort to figure out what types of questions we can ask the model and receive unreasonably effective responses.
Hunch: OpenAI’s primary goal with ChatGPT is crowdsourcing prompt engineering - finding out what its massive language model is truly capable of.
What exactly GPT-4 is capable of is still an open question, but my hunches on what kind of second wave applications will arise:
Crafting structured data from unstructured sources
Search replaced with answers (e.g. Google has been doing on a search for “London weather”)
Providing context to model to generate personalized responses
Knowledge synthesis
Knowledge creation. Tell us what the model has inferred without being told directly
The Effects on Society
For society, and for humanity, the latest strides in AI technology are significant. Like the password security challenge where the importance of letters 1-6 is negligible, but 7-12 are everything, we may just be entering the second echelon of traction. The timing and outcome of these future steps is still to be seen. I think, however, the overall impact in terms of employment and unemployment is fairly predictable and can be prepared for as such. The distribution of value contribution will become increasingly stretched out and long-tailed. Next generation AI will create yet another lever allowing those that can make use of it to produce far more value. But this dynamic is nothing new. Simply the next iteration in an ongoing trend where skilled knowledge work is greatly rewarded. Whether or not AI is the breaking straw, I believe it will push us toward some necessary changes so that we can continue to exist as a society resembling how we know it today, if indeed that is our preferred outcome. A universal basic income. Increased pay for manual labor tasks like cleaners and farmers. More approachable entry points to careers and more predictable career trajectories. Hopefully a paradigm shift in the higher education system and credentialing.
Ultimately, AI will lead to greater knowledge for humanity. The question remains, what knowledge and to what purpose shall we use it. Maybe to live longer lives. To be more entertained. To feel deeper connections. To better understand ourselves. Or maybe its all just to make better music.
https://arxiv.org/abs/1706.03762
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
https://www.ciocoverage.com/openais-chatgpt-reportedly-costs-100000-a-day-to-run/